
Perché il KEF Uni-Q di 12a generazione e l'unica fonte apparente sono significativi

di Redazione
17/02/2022



Negli ultimi 30 anni, KEF ha sviluppato oltre 50 esempi di array di driver Uni-Q, progettati specificamente per la gamma o i modelli in mente. Inoltre, queste oltre 50 iterazioni sono state raggruppate in varie generazioni. All'interno di ogni generazione, diversi Uni-Q presentano vari livelli di prestazioni, con un filo tecnologico comune.

Uni-Q è ora alla sua dodicesima generazione. Per le nuove serie Blade e The Reference, gli ingegneri KEF hanno colto l'occasione per ridefinire lo stato dell'arte e fornire un esempio tecnologico di punta dell'ultima e più grande Uni-Q di 12a generazione. Questa iterazione di Uni-Q presenta un avanzamento in ogni singolo aspetto dell'array di driver e ogni singolo componente è stato rivisto senza compromessi. Sia il midrange che il tweeter sono stati progettati da zero per questa applicazione, garantendo una perfetta integrazione di entrambi i driver in uno, sia acusticamente che come pacchetto fisico.
Per capire il significato del midrange/tweeter Uni-Q di 12a generazione aiuta a capire un po' di psicoacustica. Fondamentalmente, Uni-Q è uno sforzo eroico per affrontare ciò che è noto da decenni su come l'orecchio e il cervello elaborano il suono. Il problema, e quindi l'eroismo, è che non è così facile affrontare ciò che sappiamo dell'orecchio/cervello.
Come percepiamo il suono
Per capirlo, immagina un pianoforte in una stanza. Un pianista suona una nota. Come facciamo a sapere dove si trova il pianoforte nella stanza? Come facciamo a sapere che è un pianoforte?
Sappiamo da molti studi scientifici che l'orecchio/cervello usa il primo suono che arriva dal pianoforte per identificare la sua posizione. Abbastanza semplice. Questo ha un senso se lo metti in termini di biologia evolutiva: centinaia di migliaia di anni fa, mentre gli esseri umani si stavano evolvendo, coloro che potevano identificare con precisione dove si trovava il leone predatore sopravvivevano più spesso di quelli che non potevano. In poche parole, avere un sistema orecchio/cervello in grado di localizzare i suoni è importante. Gli umani sono bravi in questo.
Ma, se ci pensi, vogliamo anche conoscere la differenza tra il leone e un passero. Per fare ciò, l'orecchio/cervello si basa su qualcosa chiamato effetto di precedenza. In effetti, il cervello somma ciò che l'orecchio sente nei primi 25-50 millisecondi in un modo che integra tutti i suoni disponibili in "un suono". Questo sembra massimizzare le informazioni disponibili in modo che gli esseri umani possano identificare ciò che sta producendo il suono. Nel caso del nostro pianoforte, l'aggiunta dei suoni diretti e riflessi precoci è ciò che ci permette di percepire la nota suonata come proveniente da un pianoforte, non da un violino o da una chitarra. Anche gli umani sono bravi in questo e non devi nemmeno pensare consapevolmente per farlo.
Come gli altoparlanti influenzano la percezione
Questo diventa importante quando consideriamo gli altoparlanti. L'altoparlante irradia i suoni a varie angolazioni nella stanza. Idealmente, vogliamo che l'uscita dell'altoparlante rispecchi il segnale di ingresso. Non vogliamo che i violoncelli siano molto più forti e i flauti siano molto più morbidi di quanto non fossero nell'orchestra originale quando è stata registrata. Quindi, diciamo che vogliamo che l'altoparlante abbia una risposta di ampiezza piatta su tutte le frequenze musicali. Ancora una volta, abbastanza semplice. Ma ora che sappiamo che l'orecchio/cervello integra tutti i suoni in circa i primi 50 ms per percepire ciò che l'orchestra sta facendo, possiamo anche capire che vogliamo che l'altoparlante abbia la stessa risposta di ampiezza piatta fuori dall'asse principale in modo che riflessa i suoni sono naturalmente equilibrati. Il livello non deve essere lo stesso del suono diretto, ma se la risposta fuori asse esagera o diminuisce determinate frequenze, l'orecchio/cervello lo aggiungerà all'immagine sonora e farà suonare il pianoforte o la chitarra o il basso o suono del violino diverso da quello che intendevano i musicisti.
Perché Uni-Q è importante
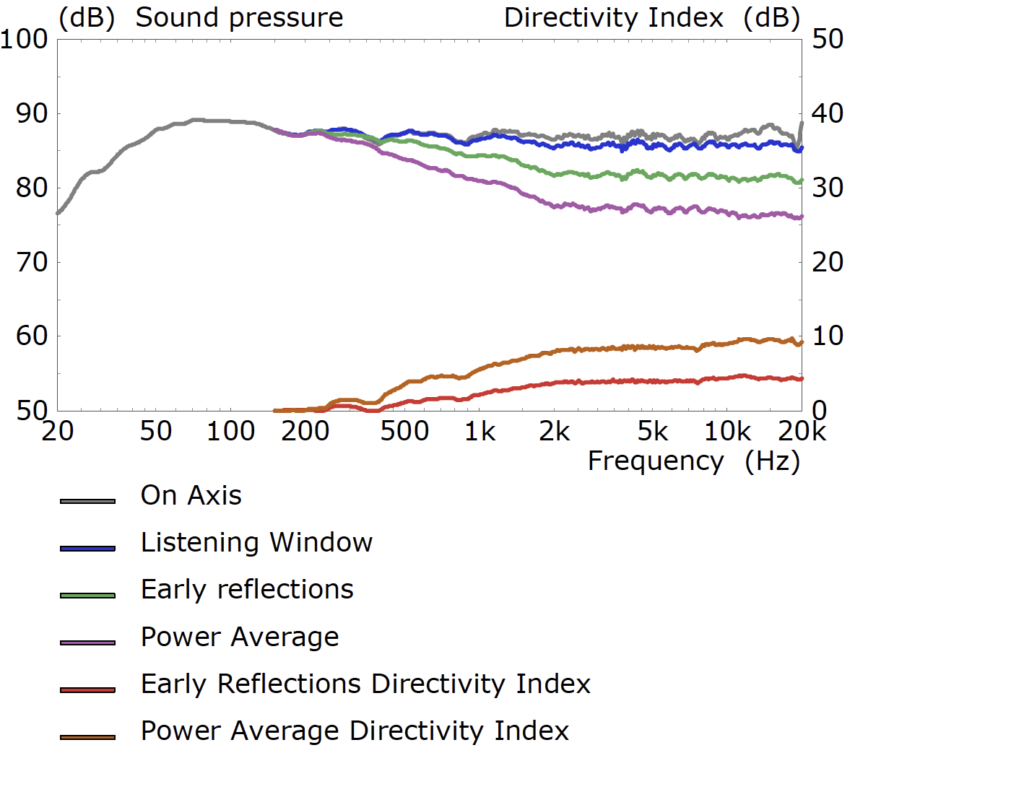
L'obiettivo di risposta fuori asse regolare in modo che le riflessioni dirette e iniziali suonino il più simili possibile non è un compito ingegneristico facile. Uni-Q combina la gamma media e il woofer per evitare interferenze tra driver e driver. Questo midrange e tweeter integrati semplificano anche l'allineamento dei tempi dei loro suoni. Fornisce inoltre una guida d'onda acustica per aiutare a rendere la risposta fuori asse della gamma media e del tweeter il più simile possibile tra le frequenze. Anche le reti crossover giocano un ruolo in questo. Puoi vedere in questo grafico come la misurazione della riflessione iniziale abbia un carattere molto simile alla misurazione della finestra di ascolto:
L'idea di Single Appparent Source, utilizzata in Blade One Meta e Blade Two Meta, è di estendere l'ingegneria per l'allineamento temporale e la risposta fuori asse regolare alle frequenze più basse. I bassi con la maggior parte degli altoparlanti sono omnidirezionali, ma dobbiamo ricordare che i driver dei bassi in genere avranno un'uscita significativa ben nella gamma media. Per un altoparlante all'avanguardia, questo sforzo in più è un altro passo verso una riproduzione musicale ideale.
Ridurre al minimo le distorsioni
E, ora che comprendiamo l'effetto di precedenza, è un po' più facile capire che vogliamo ridurre al minimo la distorsione. Aiuta ad aggiungere che gli strumenti musicali suonano in modo diverso in larga misura perché emettono suoni nel tempo. Il Do centrale su un pianoforte e una chitarra hanno la stessa frequenza, ma le risonanze e le vibrazioni della corda e del telaio del pianoforte martellato sono totalmente diverse dalle risonanze e dalle vibrazioni di una corda pizzicata. Queste risonanze e vibrazioni decadono a livelli molto bassi, ma livelli che possiamo ancora ascoltare e utilizzare per caratterizzare il suono. Quindi, se al segnale sono stati aggiunti anche piccoli componenti di distorsione, verranno aggiunti quei componenti di distorsione e la chitarra non suonerà tanto come una chitarra. Oppure una Stratocaster e una Les Paul possono suonare più simili di quanto dovrebbero.
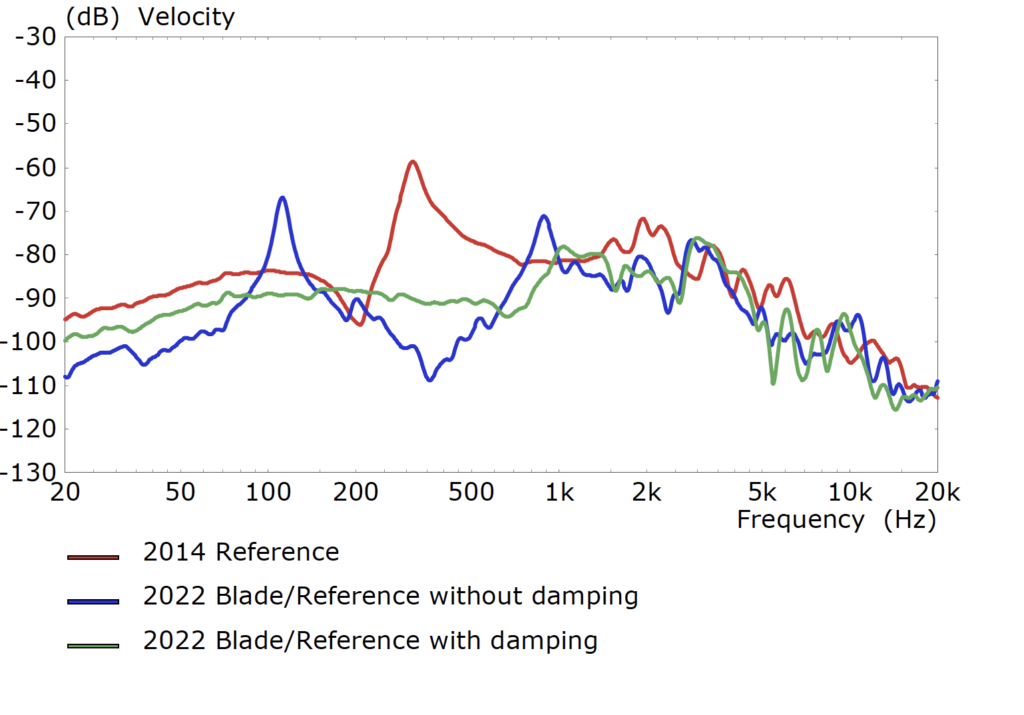
Con l'Uni-Q di 12a generazione, KEF ha affrontato una serie di distorsioni. Ad esempio, il team KEF ha scoperto che lo smorzamento elastomerico tipicamente utilizzato per isolare il driver dal cabinet consentiva comunque al cabinet o al driver di irradiare suoni sfasati nella stanza. Quindi, gli ingegneri hanno sviluppato un modo per spostare lo smorzamento all'interno del cabinet verso il retro del driver Uni-Q. Il risultato (curva verde sotto) è di appianare i picchi di risonanza che i sistemi di smorzamento più tradizionali avevano ancora:
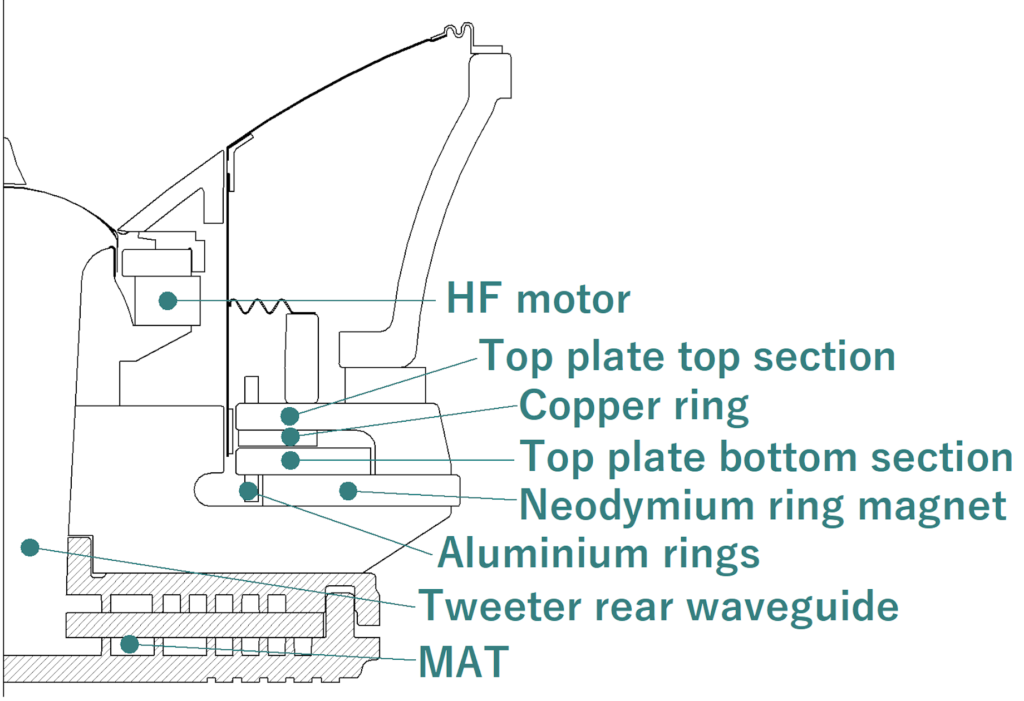
Puoi capire che imballare insieme il tweeter e la gamma media offre una serie di sfide. Ogni parte dell'array Uni-Q è stata progettata per apportare ulteriori miglioramenti, tra cui un nuovo smorzatore del gap del tweeter e un nuovo design della guida d'onda. Il driver Uni-Q ha una serie completamente nuova di sistemi motori, un nuovo spider e proprietà magnetiche avanzate.
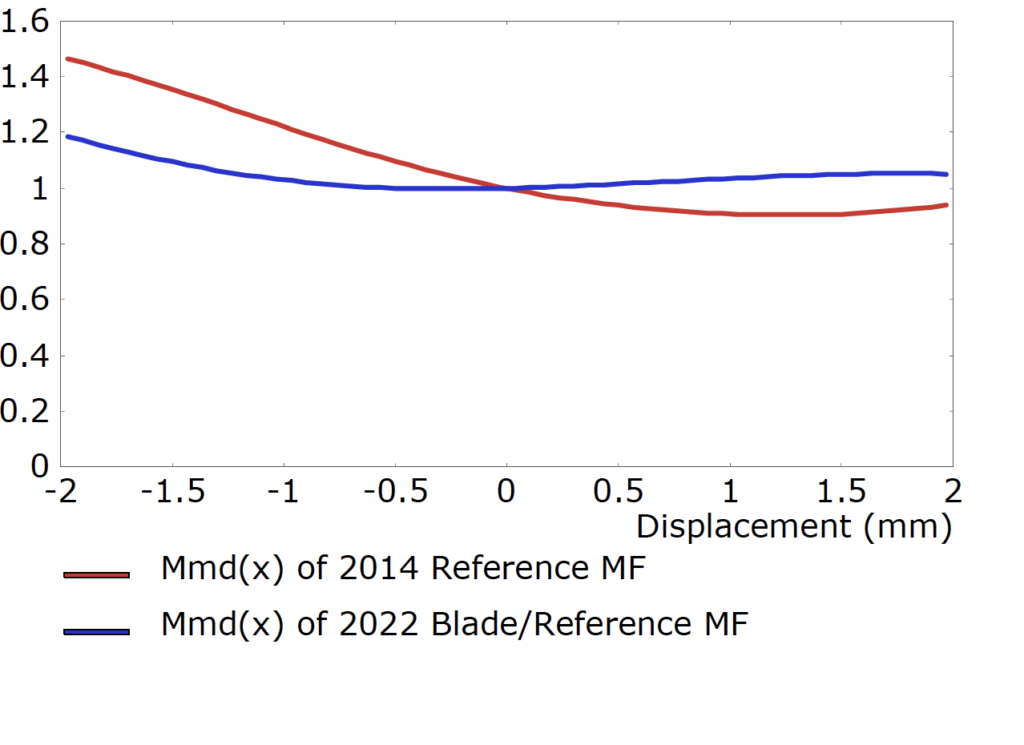
Ciò fornisce una maggiore linearità elettromagnetica ed è particolarmente efficace a livelli di uscita più elevati. Anche la massa mobile è stata migliorata. Notare la linearità migliorata della curva blu con spostamento, ad esempio:
Tecnologia di assorbimento dei metamateriali
Ci sono molti altri miglioramenti in offerta. Il più grande di questi, l'uso della tecnologia di assorbimento dei metamateriali, merita una discussione separata che troverai qui .
Il post Perché l'Uni-Q KEF di 12a generazione e la singola sorgente apparente sono significativi è apparso per la prima volta su The Absolute Sound .
Articolo Precedente
darTZeel NHB-108 modello due amplificatore di potenza
Articolo Successivo
Tecnologia di assorbimento dei metamateriali


